CREATE FOREIGN TABLE {table-name} (
<table-element> (,<table-element>)*
[<constraint> (,<constraint>)*
) OPTIONS (<options-clause>)
<table-element> ::=
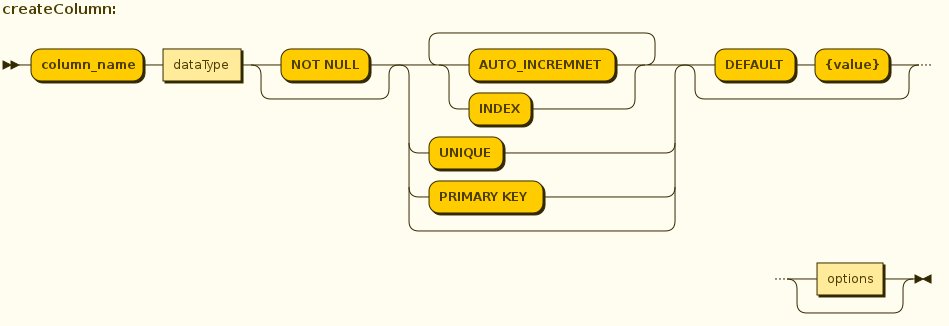
{column-name} <data-type> <element-attr> <options-clause>
<data-type> ::=
varchar | boolean | integer | double | date | timestamp .. (see Data Types)
<element-attr> ::=
[AUTO_INCREMENT] [NOTNULL] [PRIMARY KEY] [UNIQUE] [INDEX] [DEFAULT {expr}]
<constraint> ::=
CONSTRAINT {constraint-name} (
PRIMARY KEY <columns> |
FOREIGN KEY (<columns>) REFERENCES tbl (<columns>)
UNIQUE <columns> |
ACCESSPATTERN <columns>
INDEX <columns>
<columns> ::=
( {column-name} [,{column-name}] )
<options-clause> ::=
<key> <value>[,<key>, <value>]*DDL Metadata for Schema Objects
Data Types
The BNF for Data Types refer to Data Types
Creating a Foreign Table
A FOREIGN table is table that is defined on source schema that represents a real relational table in source databases like Oracle, SQLServer etc. For relational databases, Teiid has capability to automatically retrieve the database schema information upon the deployment of the VDB, if one like to auto import the existing schema. However, user can use below FOREIGN table semantics, when they would like to explicitly define tables on PHYSICAL schema or represent non-relational data as relational in custom translators.
BNF for Create Table
For validating BNF for create table refer to CREATE TABLE
Example 7:Create Foreign Table(Created on PHYSICAL model)
CREATE FOREIGN TABLE Customer (
id integer PRIMARY KEY,
firstname varchar(25),
lastname varchar(25),
dob timestamp);
CREATE FOREIGN TABLE Order (
id integer PRIMARY KEY,
customerid integer OPTIONS(ANNOTATION 'Customer primary key'),
saledate date,
amount decimal(25,4),
CONSTRAINT CUSTOMER_FK FOREGIN KEY(customerid) REFERENCES Customer(id)
) OPTIONS(UPDATABLE true, ANNOTATION 'Orders Table');TABLE OPTIONS: (the below are well known options, any others properties defined will be considered as extension metadata)
| Property | Data Type or Allowed Values | Description |
|---|---|---|
UUID |
string |
Unique identifier for View |
CARDINALITY |
int |
Costing information. Number of rows in the table. Used for planning purposes |
UPDATABLE |
'TRUE'|'FALSE' |
Defines if the view is allowed to update or not |
ANNOTATION |
string |
Description of the view |
DETERMINISM |
NONDETERMINISTIC, COMMAND_DETERMINISTIC, SESSION_DETERMINISTIC, USER_DETERMINISTIC, VDB_DETERMINISTIC, DETERMINISTIC |
Only checked on source tables |
COLUMN OPTIONS: (the below are well known options, any others properties defined will be considered as extension metadata)
| Property | Data Type or Allowed Values | Description |
|---|---|---|
UUID |
string |
A unique identifier for the column |
NAMEINSOURCE |
string |
If this is a column name on the FOREIGN table, this value represents name of the column in source database, if omitted the column name is used when querying for data against the source |
CASE_SENSITIVE |
'TRUE'|'FALSE' |
|
SELECTABLE |
'TRUE'|'FALSE' |
TRUE when this column is available for selection from the user query |
UPDATABLE |
'TRUE'|'FALSE' |
Defines if the column is updatable. Defaults to true if the view/table is updatable. |
SIGNED |
'TRUE'|'FALSE' |
|
CURRENCY |
'TRUE'|'FALSE' |
|
FIXED_LENGTH |
'TRUE'|'FALSE' |
|
SEARCHABLE |
'SEARCHABLE'|'UNSEARCHABLE'|'LIKE_ONLY'|'ALL_EXCEPT_LIKE' |
column searchability, usually dictated by the data type |
MIN_VALUE |
||
MAX_VALUE |
||
CHAR_OCTET_LENGTH |
integer |
|
ANNOTATION |
string |
|
NATIVE_TYPE |
string |
|
RADIX |
integer |
|
NULL_VALUE_COUNT |
long |
costing information. Number of NULLS in this column |
DISTINCT_VALUES |
long |
costing information. Number of distinct values in this column |
Columns may also be marked as NOT NULL, auto_increment, and with a DEFAULT value.
A column of type bigdecimal/decimal/numeric can be declared without a precision/scale which will default to an internal maximum for precision with half scale, or with a precision which will default to a scale of 0.
Defining Table CONSTRAINTS
Constraints can be defined on table/view to define indexes and relationships to other tables/views. This information is used by the Teiid optimizer to plan queries or use the indexes in materialization tables to optimize the access to the data.
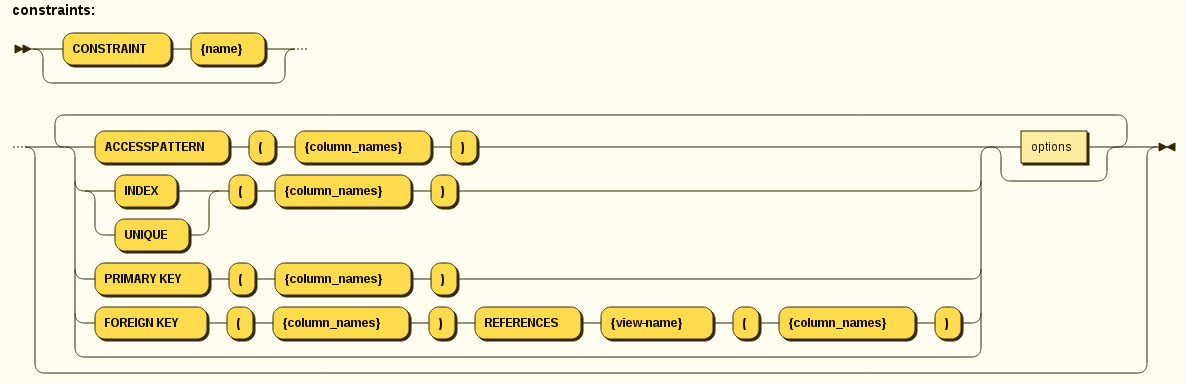
CONSTRAINTS are same as one can define on RDBMS.
Example of CONSTRAINTs
CREATE FOREIGN TABLE Orders (
name varchar(50),
saledate date,
amount decimal,
CONSTRAINT CUSTOMER_FK FOREGIN KEY(customerid) REFERENCES Customer(id)
ACCESSPATTERN (name),
PRIMARY KEY ...
UNIQUE ...
INDEX ...ALTER TABLE
The BNF for ALTER table, refer to ALTER TABLE
Using the ALTER COMMAND, one can Add, Change, Delete columns, and/or modify any OPTIONS values. Some examples below.
-- add column to the table
ALTER FOREIGN TABLE "Customer" ADD COLUMN address varchar(50) OPTIONS(SELECTABLE true);
-- remove column to the table
ALTER FOREIGN TABLE "Customer" DROP COLUMN address;
-- adding options property on the table
ALTER FOREIGN TABLE "Customer" OPTIONS (ADD CARDINALITY 10000);
-- Changing options property on the table
ALTER FOREIGN TABLE "Customer" OPTIONS (SET CARDINALITY 9999);
-- Changing options property on the table's column
ALTER FOREIGN TABLE "Customer" ALTER COLUMN "name" OPTIONS(SET UPDATABLE FALSE)
-- Changing table's column type to integer
ALTER FOREIGN TABLE "Customer" ALTER COLUMN "id" TYPE bigdecimal;
-- Changing table's column column name
ALTER FOREIGN TABLE "Customer" RENAME COLUMN "id" TO "customer_id";Create View
A view is a virtual table. A view contains rows and columns,like a real table. The columns in a view are columns from one or more real tables from the source or other view models. They can also be expressions made up multiple columns, or aggregated columns. When column definitions are not defined on the view table, they will be derived from the projected columns of the view’s select transformation that is defined after the AS keyword.
You can add functions, JOIN statements and WHERE clauses to a view data as if the data were coming from one single table.
BNF for Create View
CREATE VIEW {table-name} AS {transformation_query}
OPTIONS (<options-clause>)
<options-clause> ::=
<key> <value>[,<key>, <value>]*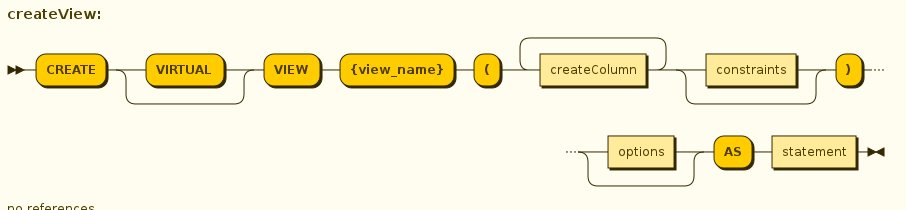
VIEW OPTIONS: (These properties are in addition to properties defined in the CREATE TABLE )
| Property | Data Type or Allowed Values | Description |
|---|---|---|
MATERIALIZED |
'TRUE'|'FALSE' |
Defines if a table is materialized |
MATERIALIZED_TABLE |
'table.name' |
If this view is being materialized to a external database, this defines the name of the table that is being materialized to |
Example:Create View Table(Created on VIRTUAL schema)
CREATE VIEW CustomerOrders
AS
SELECT concat(c.firstname, c.lastname) as name,
o.saledate as saledate,
o.amount as amount
FROM Customer C JOIN Order o ON c.id = o.customerid;|
Important
|
Note that the columns are implicitly defined by the transformation query (SELECT statement), they can also defined inline but if they are defined they can be only altered to modify their properties, you can not ADD or DROP new columns. |
ALTER TABLE
The BNF for ALTER VIEW, refer to ALTER TABLE
Using the ALTER COMMAND you can change the transformation query of the VIEW. You are NOT allowed to Alter the column information. Also the transformation query must be valid
ALTER VIEW CustomerOrders
AS
SELECT concat(c.firstname, c.lastname) as name,
o.saledate as saledate,
o.amount as amount
FROM Customer C JOIN Order o ON c.id = o.customerid
WHERE saledate < TIMESTAMPADD(now(), -1, SQL_TSI_MONTH)INSTEAD OF TRIGGERS On VIEW (Update VIEW)
A view comprising multiple base tables must use an INSTEAD OF trigger to support inserts, updates and deletes that reference data in the tables. Based on the select transformation’s complexity some times INSTEAD OF TRIGGERS are automatically provided for the user when "UPDATABLE" OPTION on the VIEW is set to "TRUE". However, using the CREATE TRIGGER mechanism user can provide/override the default behavior.
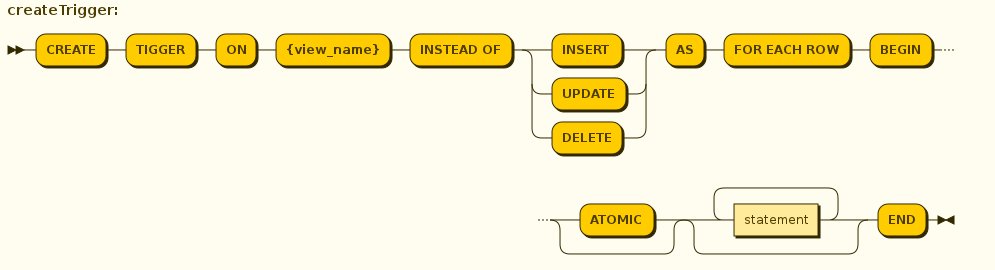
Example:Define instead of trigger on View for INSERT
CREATE TRIGGER ON CustomerOrders INSTEAD OF INSERT AS
FOR EACH ROW
BEGIN ATOMIC
INSERT INTO Customer (...) VALUES (NEW.name ...);
INSERT INTO Orders (...) VALUES (NEW.value ...);
ENDFor Update
Example:Define instead of trigger on View for UPDATE
CREATE TRIGGER ON CustomerOrders INSTEAD OF UPDATE AS
FOR EACH ROW
BEGIN ATOMIC
IF (CHANGING.saledate)
BEGIN
UPDATE Customer SET saledate = NEW.saledate;
UPDATE INTO Orders (...) VALUES (NEW.value ...);
END
ENDWhile updating you have access to previous and new values of the columns. For more detailed explanation of these update procedures please refer to Update Procedures
AFTER TRIGGERS On Source Tables
A source table can have any number of uniquely named triggers registered to handle change events that are reported by a change data capture system.
Similar to view triggers AFTER insert provides access to new values via the NEW group, AFTER delete provides access to old values via the OLD group, and AFTER update provides access to both.
Example:Define AFTER trigger on Customer
CREATE TRIGGER ON Customer AFTER INSERT AS
FOR EACH ROW
BEGIN ATOMIC
INSERT INTO CustomerOrders (CustomerName, CustomerID) VALUES (NEW.Name, NEW.ID);
ENDYou will typically define a handler for each operation - INSERT/UPDATE/DELTE.
For more detailed explanation of these update procedures please refer to Update Procedures
Create Procedure/Function
Using the below syntax, user can define a
-
Source Procedure ("CREATE FOREIGN PROCEDURE") - a stored procedure in source
-
Source Function ("CREATE FOREIGN FUNCTION") - A function that is supported by the source, where Teiid will pushdown to source instead of evaluating in Teiid engine
-
Virtual Procedure ("CREATE VIRTUAL PROCEDURE") - Similar to stored procedure, however this is defined using the Teiid’s Procedure language and evaluated in the Teiid’s engine.
-
Function/UDF ("CREATE VIRTUAL FUNCTION") - A user defined function, that can be defined using the Teiid procedure language or can have the implementation defined using a JAVA Class.
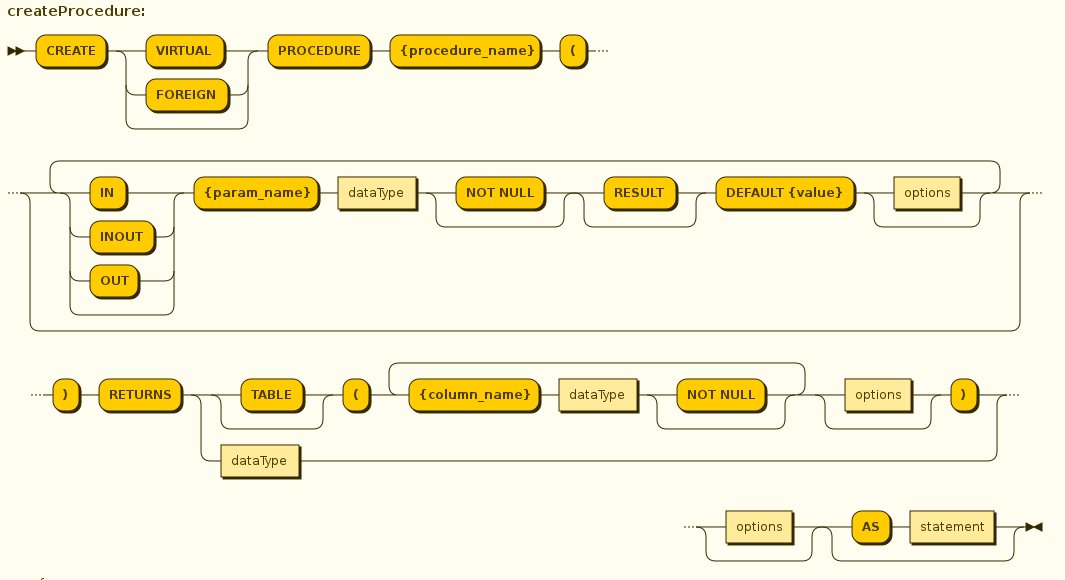
See the full grammar for create function/procedure in the BNF for SQL Grammar.
Variable Argument Support
Instead of using just an IN parameter, the last non optional parameter can be declared VARIADIC to indicate that it can be repeated 0 or more times when the procedure is called
Example:Vararg procedure
CREATE FOREIGN PROCEDURE proc (x integer, VARIADIC z integer)
RETURNS (x string);FUNCTION OPTIONS:(the below are well known options, any others properties defined will be considered as extension metadata)
| Property | Data Type or Allowed Values | Description |
|---|---|---|
UUID |
string |
unique Identifier |
NAMEINSOURCE |
If this is source function/procedure the name in the physical source, if different from the logical name given above |
|
ANNOTATION |
string |
Description of the function/procedure |
CATEGORY |
string |
Function Category |
DETERMINISM |
NONDETERMINISTIC, COMMAND_DETERMINISTIC, SESSION_DETERMINISTIC, USER_DETERMINISTIC, VDB_DETERMINISTIC, DETERMINISTIC |
Not used on virtual procedures |
NULL-ON-NULL |
'TRUE'|'FALSE' |
|
JAVA_CLASS |
string |
Java Class that defines the method in case of UDF |
JAVA_METHOD |
string |
The Java method name on the above defined java class for the UDF implementation |
VARARGS |
'TRUE'|'FALSE' |
Indicates that the last argument of the function can be repeated 0 to any number of times. default false. It is more proper to use a VARIADIC parameter. |
AGGREGATE |
'TRUE'|'FALSE' |
Indicates the function is a user defined aggregate function. Properties specific to aggregates are listed below. |
Note that NULL-ON-NULL, VARARGS, and all of the AGGREGATE properties are also valid relational extension metadata properties that can be used on source procedures marked as functions. See also Source Supported Functions for creating FOREIGN functions that are supported by a source.
AGGREGATE FUNCTION OPTIONS:
| Property | Data Type or Allowed Values | Description |
|---|---|---|
ANALYTIC |
'TRUE'|'FALSE' |
indicates the aggregate function must be windowed. default false. |
ALLOWS-ORDERBY |
'TRUE'|'FALSE' |
indicates the aggregate function supports an ORDER BY clause. default false |
ALLOWS-DISTINCT |
'TRUE'|'FALSE' |
indicates the aggregate function supports the DISTINCT keyword. default false |
DECOMPOSABLE |
'TRUE'|'FALSE' |
indicates the single argument aggregate function can be decomposed as agg(agg(x) ) over subsets of data. default false |
USES-DISTINCT-ROWS |
'TRUE'|'FALSE' |
indicates the aggregate function effectively uses distinct rows rather than all rows. default false |
Note that virtual functions defined using the Teiid procedure language cannot be aggregate functions.
|
Note
|
Providing the JAR libraries - If you have defined a UDF (virtual) function without a Teiid procedure deinition, then it must be accompanied by its implementation in Java. To configure the Java library as dependency to the VDB, see Support for User-Defined Functions |
PROCEDURE OPTIONS:(the below are well known options, any others properties defined will be considered as extension metadata)
| Property | Data Type or Allowed Values | Description |
|---|---|---|
UUID |
string |
Unique Identifier |
NAMEINSOURCE |
string |
In the case of source |
ANNOTATION |
string |
Description of the procedure |
UPDATECOUNT |
int |
if this procedure updates the underlying sources, what is the update count, when update count is >1 the XA protocol for execution is enforced |
Example:Define virtual Procedure
CREATE VIRTUAL PROCEDURE CustomerActivity(customerid integer)
RETURNS (name varchar(25), activitydate date, amount decimal)
AS
BEGIN
...
ENDRead more information about virtual procedures at Virtual Procedures, and these procedures are written using Procedure Language
Example:Define Virtual Function
CREATE VIRTUAL FUNCTION CustomerRank(customerid integer)
RETURNS integer AS
BEGIN
...
ENDProcedure columns may also be marked as NOT NULL, or with a DEFAULT value. On a source procedure if you want the parameter to be defaultable in the source procedure and not supply a default value in Teiid, then the parameter must use the extension property teiid_rel:default_handling set to omit.
There can only be a single RESULT parameter and it must be an out parameter. A RESULT parameter is the same as having a single non-table RETURNS type. If both are declared they are expected to match otherwise an exception is thrown. One is no more correct than the other. "RETURNS type" is shorter hand syntax especially for functions, while the parameter form is useful for additional metadata (explicit name, extension metadata, also defining a returns table, etc.).
A return parameter will be treated as the first parameter in for the procedure at runtime, regardless of where it appears in the argument list. This matches the expectation of Teiid and JDBC calling semantics that expect assignments in the form "? = EXEC …".
Relational Extension OPTIONS:
| Property | Data Type or Allowed Values | Description |
|---|---|---|
native-query |
Parameterized String |
Applies to both functions and procedures. The replacement for the function syntax rather than the standard prefix form with parens. See also Translators#native |
non-prepared |
boolean |
Applies to JDBC procedures using the native-query option. If true a PreparedStatement will not be used to execute the native query. |
Example:Native Query
CREATE FOREIGN FUNCTION func (x integer, y integer)
RETURNS integer OPTIONS ("teiid_rel:native-query" '$1 << $2');Example:Sequence Native Query
CREATE FOREIGN FUNCTION seq_nextval ()
RETURNS integer
OPTIONS ("teiid_rel:native-query" 'seq.nextval');|
Tip
|
Until Teiid provides higher-level metadata support for sequences, a source function representation is the best fit to expose sequence functionality. |
Extension Metadata
When defining the extension metadata in the case of Custom Translators, the properties on tables/views/procedures/columns can define namespace for the properties such that they will not collide with the Teiid specific properties. The property should be prefixed with alias of the Namespace. Prefixes starting with teiid_ are reserved for use by Teiid.

Example of Namespace
SET NAMESPACE 'http://custom.uri' AS foo
CREATE VIEW MyView (...)
OPTIONS ("foo:mycustom-prop" 'anyvalue')Built-in Namespace Prefixes
| Prefix | URI | Description |
|---|---|---|
teiid_rel |
Relational extensions. Uses include function and native query metadata |
|
teiid_sf |
Salesforce extensions. |
|
teiid_mongo |
MongoDB Extensions |
|
teiid_odata |
OData Extensions |
|
teiid_accumulo |
Accumulo extensions |
|
teiid_excel |
Excel Extensions |
|
teiid_ldap |
LDAP Extensions |
|
teiid_rest |
REST Extensions |
|
teiid_pi |
PI Database Extensions |